Museums and Modern Data Stores for Connected Data
Over the past six months I have been doing some thinking (and a little bit of coding) about database schema and interface designs that would support hosting any information about any museum collection. One major goal of my design planning is to think about a museum database as more than just a database of transcribed label data or a management solution for knowing where objects are location. Ideally I think a museum datastore should be a rich collection of metadata that allows for linking individual objects to each other as well as to the digital resources associated with the collection.My current position as a
Database Engineering Decisions
In my opinion an ideal database system for museum collections will have the following properties:- Interoperability - An open schema design and data store that can interoperate internally with existing software resources as well as be able to interoperate with external resources such as centralized metadata warehouses like iDigBio or GBIF as well as archival media repositories such as DLXS, Hathi Trust or the Digital Preservation Network.
- Flexibility - Can store any meta-data about a museum collection or museum object as well as any digital media associated with that item. Ideally this will not be limited to just a label transcription, but can store phenotypic measurement data directly in the data store. Slight changes to the type of data that you want to store should not require any modifications of the underlying tables in the database.
- Linkability - Data about museum objects can be effectively linked to existing or newly derived resources about that object. This allows for queries that link information about the object across multiple domains of knowledge. This allows for the all important JOIN queries. External data for museum objects include but are not limited to:
- Molecular sequence data such genome scale molecular sequence data associated with an accession. These range from whole genome sequence assemblies to SNP and
- Literature references to the use of the object (ie. objects used in phylogenetic studies or population natural diversity studies) and the description that object (ie. type specimens)
- Digital media collected in the field or derived once the object has been accessioned
- Collections objects can be linked to a named collection and individual objects can be associated with more than one collection
- Stability - Stability means the underlying schema and database storage software passes the ACID test. The data store needs to be a reliable archival quality data store.
I think that that the weak-data typing paradigm that has been employed in open source genomic databases can be effectively combined with existing ideas on generating shared open and connected data for museums. I have therefore tried to combined these ideas in the database engineering decisions that I've made to create a flexible museum data storage system. The key concepts I have incorporated in a an RDBMS schema for museum collections are:
- Weak-data typing - The weak data typing paradigm allows for storing any information about an object. This system is designed for archival quality storage of meta data and is not indexed for speedy retrieval of specific types of data. Think of this as a way of storing museum data in archival boxes for retrieval similar to the way we use general purpose compactors to store museum objects in a space efficient manner. We can use this system express the data in other formats such as RDF for speedy task specific queries.
- Controlled Vocabularies - The use of controlled vocabularies provides the means for connected information about an object to a dictionary of what that information is. Ideally this would be a vocabulary that is based on a published ontology. Most importantly the system allows for mapping among controlled vocabularies. Thus it is possible to translate a system one dictionary of terms to another dictionary of terms. For example, we can translate information in an internal set of terms to Darwin Core terms.
- GUIDs - Globally Unique Identifiers (GUIDs) are the cornerstone for building the web of connected data.
- Nested set model - Objects in collections follow the nested set model object representation. This allows for tracking parent-child relationships of museum objects. For example genome information about an individual egg, collected from an individual fish specimen in jar of multiple fish can be tracked as three sets of meta-data that are connected and query-able.
The MuseSQL Schema
I chose to start by engineering a museum specific module extension to the Chado database schema. I called the SQL extension module for museum data MuseSQL (pronounced ♪musical♫) since this is a Museum SQL store. I chose to use Chado due to 1) it's wide use in genomics as part of GMOD, 2) a large library of existing interoperable modules and 3) my familiarity with loading both OBO and OWL ontologies into the Chado controlled vocabulary tables.
Information on how to store and use controlled vocabulary tables in Chado have been extensively discussed elsewhere (Mungall et al, CV module documentation) so I will just generally outline them here. The Chado CV terms allow for any type of information about an object to be stored in a stable way that can be referenced back to a definition of what that term means. Since this method includes support for the storing relationships among terms, we can also store these definitions as an ontology. The database even allows for mapping the relationship among terms from different ontologies to be stored in the same database. Thus it is possible to use the relationship table to store a cross referenced set of terms mapped onto another set of terms. For example, it is a straightforward exercise to map terms from an existing set of ad-hoc database columns to Darwin core terms, or to map Darwin Core terms to another controlled vocabularies such as schema.org.
Information on how to store and use controlled vocabulary tables in Chado have been extensively discussed elsewhere (Mungall et al, CV module documentation) so I will just generally outline them here. The Chado CV terms allow for any type of information about an object to be stored in a stable way that can be referenced back to a definition of what that term means. Since this method includes support for the storing relationships among terms, we can also store these definitions as an ontology. The database even allows for mapping the relationship among terms from different ontologies to be stored in the same database. Thus it is possible to use the relationship table to store a cross referenced set of terms mapped onto another set of terms. For example, it is a straightforward exercise to map terms from an existing set of ad-hoc database columns to Darwin core terms, or to map Darwin Core terms to another controlled vocabularies such as schema.org.
The core concepts regarding museum collections that exist in the MuseSQL module include:
- Museum objects - These are the physical object in a museum collections. This is about the stuff .. be it jars of fish, pressed plants, boxes of seeds etc.
- Digital objects - These are any type of digital resources including image scans of an object, images captured in the field, audio capture in the field, 3d scans of an object etc. I don't require a dependency between a digital object and a museum physical object so that digital media captured by a museum can be held even when there is not voucher for that digital object. This could for example include recordings of birdsong captured in the field, or digital photographs taken in association .
- Collection - A collection of museum objects or digital objects
- Transactions - Time delineated events that concern a collection or object. This can include accessioning, de-accessioning, loans or transfer to another institution.
- Institutions - Including the people and places associated with a museum or a transaction among museums
An initial implementation of this design has been developed in MySQL. An overview of the schema for the museum module tables and the controlled vocabulary tables looks like the following:

These tables are outline in more detail below, but this gives the birds-eye view of the design and shows the general links among concepts. The table names all follow Chado naming conventions in which names of tables are in all lowercase and do not have spaces or special characters. Linker tables have a '_' character naming the two tables that they link.
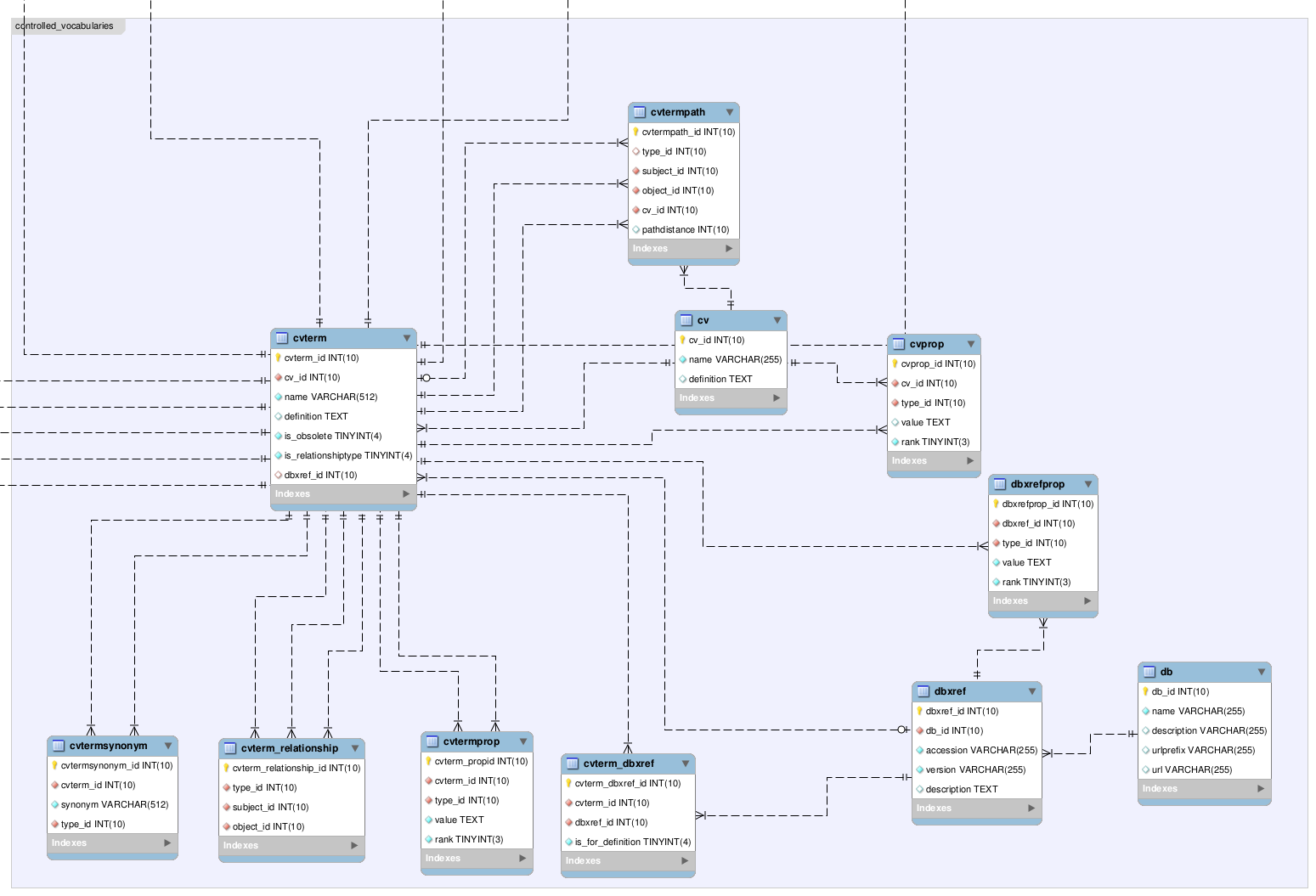
Controlled Vocabularies
The controlled vocabulary tables are what support the tagging of properties of objects within the collection. These tables are discussed in detail in the the Chado documentation of the CV module, and are represented here to show how the MuseSQL tables connect to the controlled vocabulary tables.
Museum Objects
The museum objects represent the physical items that a individual museum unit is responsible for curating.
The tables for museum objects include:
- muso - the main museum object table. This is the table that represents an individual item in a museum. There are some important columns here that are worth pointing out:
- muso_parent_id - this column allows for individual items to be associated with a parent item. For example if we want to store measurement information of the individuals from a jar of multiple fish. The individual fish can be treated as objects that are children of the jar object. The jar object would be used to record the label information, while the individual fish objects would be used to store the phenotypic measurement data.
- left_index & right_index - these are the indexes that provide nested-set model support of storing the collection data such that it is possible to do a search for all child objects for a given parent object
- guid - this is the GUID for the individual item. It would have been possible to provide support for GUIDs in the musprop table, but I wanted to store a single GUID within the table as a column to allow for quick queries and indexes against the GUID. This would be the internal institutional GUID. The musoprop table would support any additional GUIDs for that item. For example a GUID assigned by iDigBio could be supported in the database.
- institution_id - is the institution that owns the object. This column allows for multiple museum units within a single university to share a single datastore while allowing for custom queries about just the items that an individual unit is responsible for. It also allows for a datastore to include metadata for museum objects that were borrowed from another institution.
- catalog_number - supports an internal catalog number that may or may-not be a GUID. If the item has multiple additional historical catalog numbers, these can all be supported in the musoprop table. This allows for institutions to maintain historical catalog numbers that are not GUID compliant.
- musoprop - properties of a museum object, for example we would have a row each for each bit of data derived from a specimen label (collector, collection date, verbatum_longitude, verbatum_latidtude etc)
- museloc - a physical location within a museum. This could be a cabinet, compactor display case etc. This is where the item is physically located.
- muselocprop - A property of a museum object location
- musocol - A collection of museum objects
- musocolprop - Properties of the collection of museum object.
Digital Objects
Digital objects are the digital assets association with a museum collection. These could really by any digital data that the museum is responsible for the curation of.

The digital object tables include:
- digo - a digital object. The digital object could be things like a sound recording from the field, an image of a specimen, a 3D scan of a specimen, a DNA sequence tracefile associated with a specimen or any other digital media that may need to be curated by a museum.
This table includes a GUID for the digital object as well as a DOI for an archival location of the digital object. The use of both a GUID and a DOI may be redundant, but I can see cases where an object may need to have a GUID before a DOI can be associated with it. - digoprop - a property of the digital object. This would be any metadata associated with the digital object and could include things like EXIF data from an image.
- digocol - a collection of digital objects. Individual objects can be associated with more than one collection.
- digocol - a property of the collection of digital objects.
- digocol_digo - a linker table that allows for indivudal digital objects to be linked into a digital collection. It is possible for individual objects to be part of one or more collections, or to not be part of any collection at all
- digo_muso - a linker table that allows for digital objects to be linked to museum objects. This is what allows for museum specimens to be linked to digital information (such as image scans) about that specimen. This would allow for meta-data such as label information to remain linked to the physical object, while the digital objects would just need to record information about the digital asset. Thus multiple images of an object from multiple angles could be stored without any need for a redundancy in the meta-data about the object.
Institutions
The institution tables record the people and places associate with transactions of museum resources. I would possibly replace the institution tables below with contact module tables from Chado if I can work out a system for reliably using the contact tables in chado to derive links to the transactions table of MuseSQL. One key difference between the chado module and the MuseSQL tables is that the institution and person tables below allow for GUIDs to be associated with the people and places. For example, person GUIDS could make use of ORCIDs.

The tables include:
- person - the person associated with a transaction.
- personprop - a property associated with that person. this is where you would store information like address, contact email, phone number etc
- institution - an institution. This would be the institution that owns objects within a collection (for example UMMZ or MICH), or another external institution that is involved in a transaction event.
- institutionprop - the properties of the institution.
- institution_person - allows for the association of individuals with an institution or multiple institutions
- institution_person - allows for describing the nature of the association with an institution, ie curator, professor, volunteer, docent etc.
Transactions
Transactions are any time-delineated event that affects a collection of museum objects. This could be a loan, a set of accessions, a set of deaccessions, a pesticide treatment for a collection, a transfer to another internal unit or any other transaction or event that occurs to a collection of objects. Since a collection of objects can be just a single object, then this supports any size collection ranging from one to all of the items in the collection. Thus transactions can support any set of things in your collection. It is possible in this schema for an object to be part of many different collections so it is possible for the many different types of transactions to be recorded for any one item in the collection.
Transaction records include the following tables:
- musocol_transaction - named currently as a linker table since it is linking a person that is responsible for a transaction to the set of objects that is involved in the transaction
- musocol_transactionprop - a property of the transaction
Meeting the Engineering Goals
Looking back the the engineering goals for the database we can consider how the MuseSQL schema meets those goals:
- Interoperability - Since this model is based on an open source MySQL RDBMS language there are many systems that can directly connect to the underlying data store. This includes programming languages like Java, Perl, and PHP as well as data visualization and analysis interfaces such a R or Tableau. It is therefore possible to build many types of GUIs to access and display the underlying database in the language of your choice. It is also possible to translate the MySQL code to support a PostgreSQL RDBMS or other RDMBS and thus have the MuseSQL schema available from many other RDBMS storage system. Even better the design principles of the data store allow the RDBMS to be translated to a RDF triple store which would make the data available in federated queries.
- Flexibility - This system can store truly store any information about a museum resource. Modifications in the type of data that users want to store in the database only require a modification or addition to the records in the controlled vocabularies. The MuseSQL table designs do not change with changing needs in data storage, and thus development of an API and GUI against the database can rely on a stable table structure.
- Linkability - The digo_muso table allows digital objects to be linked to physical objects in a museum and both the museum object set and digital object set have tables that allow for combining objects into collections. Although physical objects can be linked to digital resources, it is also possible for digital objects and physical museum objects to stand alone without any sort of dependency on a physical resource or digital record.
It is also possible to link the museum objects to the following data and analysis modules via linker tables - Chado Publication Module to store references to and about the object in the literature
- Chado Sequence Module to store sequence data derived from museum specimens
- Chado Natural Diversity Module to store genotyping and phenotype data associated with collections
- Chado Comparative Analysis Module to store sequence comparative analysis data
- Chado Mage Module to store data derived from microarray experiments
- Chado Contact Module could even be used instead of the instituion tables above
- Chado Phylogeny Module would allow for museum speciments to be directly connected to phylogenetics. This would allow for phylogenetically informed searches of the database.
- Chado Organisms Module could hold a taxonomic reference list
- Stability - MySQL complies with ACID, and the workflows for data entry and deletion can be controlled to make MuseSQL a stable archival quality database resource.
Wolverines are Gluttons
General methods for connecting to the MuseSQL data store would ideally involve the development of an API that treats the dataset as a collection of Globally Unique Linked Objects. Since I am employed as a UM wolverine, Gulo seemed like the appropriate name for the API and data collection framework. Wolverines (Gulo gulo) are gluttons that are not very finnickey about what they eat and will consume carrion fast. So what better name for a flexible museum database system that could quickly consume any information for any object. GULO also references the basic idea that objects in the collection would be assigned a globally unique identifier in a way that allows objects and meta-data to be universally linked to each other.

One important outcome from this design is that it allows for a RDBMS archival storage system that can be forward translated to RDF triple-stores. Since the system integrates GUIDs and controlled vocabularies, it is a very simple matter to translate these data into to representative triple stores that can be hosted online and used in federated queries of RDF stores.
So Where are GULO and MuseSQL?
The MuseSQL schema is currently a test framework that exists only on my laptop as MySQL tables and SQL code. The code is and backed up to our LSA/MIS SVN server but is currently not deployed anywhere in production. I have written code to consume ontologies and vocabularies such as Darwin Core and have tested the ability to tag test museum specimen data. Although the MuseSQL schema is not something that is currently in production at UM, I would hope to have the opportunity to develop aspects of MuseSQL and GULO in the near future. I just wanted to put this blog post out there to get public feedback on the schema now rather than years down the road when it would be less helpful.My Opinions are my own and do not reflect the opinions of the University of Michigan, the UM College of Literature and Science and Arts, the Management Information Systems group, the University of Michigan Museum Units or any wolverines.
No comments:
Post a Comment